Langchain RAG를 활용해서 내 마켓이 있다고 생각하고 고객센터 챗봇을 만들어 볼 것이다.
AI를 하면서 항상 중요한 것중에 하나인데 무조건 데이터가 필수적으로 필요하다.
아래의 이번 챗봇에서 사용될 데이터다. 데이터는 고객센터에 맞게 질문과 답변으로 돼있다.
{
"input": "제 주문이 언제 배송되나요?",
"response": "고객님, 주문하신 상품은 오늘 출발 예정이며, 2~3일 내에 도착할 예정입니다. 자세한 배송 추적은 배송 조회에서 확인하실 수 있습니다."
},
{
"input": "주문 취소하고 싶은데 어떻게 해야 하나요?",
"response": "주문 취소는 상품 출발 전까지 가능하며, 고객센터를 통해 취소 요청을 하실 수 있습니다. 주문 상태를 확인 후 빠르게 처리해드리겠습니다."
},
{
"input": "상품에 하자가 있는 것 같아요. 어떻게 해야 하나요?",
"response": "고객님, 불편을 드려 죄송합니다. 상품의 하자 부분에 대한 사진을 보내주시면 교환 또는 환불 절차를 진행하도록 하겠습니다."
},
{
"input": "적립금이 어떻게 사용되나요?",
"response": "적립금은 구매 금액에 따라 자동으로 적용되며, 결제 시 사용하실 수 있습니다. 적립금 사용 가능 금액은 결제 화면에서 확인 가능합니다."
},
순서
- jsonData → VectorDB
- rag를 활용한 chatBot구현
- 화면구현
1. jsonData → VectorDB
jsonData를 불러온다.
with open("custommer_qna.json", "r", encoding="utf-8") as f:
json_data = json.load(f)
불러온 데이터는 vector Database에 저장하기 위해서는 embedding를 해야된다.
gpt, llama, bedrock등 여러가지가 있으니 원하는걸로 하면된다.
embeddings = BedrockEmbeddings(
model_id="amazon.titan-embed-text-v2:0",
region_name="ap-northeast-2"
)
모델을 불러왔으니 이번에는 vector database에 저장할 수 있게 Document형식으로 json데이터를 변경시켜줄 것이다.
raw_documents = []
for item in json_data:
input_text = item.get("input", "")
response_text = item.get("response", "")
content = f"Input: {input_text}\\nResponse: {response_text}"
raw_documents.append(Document(page_content=content, metadata=metadata))
Document형식으로 데이터를 만든후에는 splitter를 사용해서 문서를 분할해줘야 한다. 만약 문서가 너무 크다면은 성능의 저하가 올 수 있기때문이다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=600, chunk_overlap=50)
documents = text_splitter.split_documents(raw_documents)
- RecursiveCharacterTextSplitter말고도 여러 splitter이 있는데 상황에 맞게 사용하는게 좋다.
- RecursiveJsonSplitter도 있는데 위에방법이 편해서 사용했다.
Input: 제 주문이 언제 배송되나요?
Response: 고객님, 주문하신 상품은 오늘 출발 예정이며, 2~3일 내에 도착할 예정입니다. 자세한 배송 추적은 배송 조회에서 확인하실 수 있습니다.
FAISS를 사용해서 vector데이터를 저장해주면 vectorDB를 만든것이다. 이제 이거를가지고 RAG를 구현해볼 수 있다.
vectorstore = FAISS.from_documents(documents, embeddings)
vectorstore.save_local("json-docs-index")
2. rag를 활용한 chatBot구현
아래의 3개를 기본적으로 불러와준다.
# 임베딩 모델을 초기화합니다.
embeddings = BedrockEmbeddings(
model_id="amazon.titan-embed-text-v2:0",
region_name="ap-northeast-2"
)
# 챗봇 모델을 초기화합니다.
llm = ChatBedrock(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
region_name="ap-northeast-2",
temperature=0
)
# 로컬에서 FAISS 인덱스를 로드합니다.
vector_db = FAISS.load_local(
INDEX_NAME,
embeddings,
allow_dangerous_deserialization=True
)
해당부분은 create_stuff_documents_chain를 사용해서 문서검색을 통해 검색된 context를 통해서 답변을 재구성하는 역할을 한다.
retrieval_qa_chat_prompt = ChatPromptTemplate.from_messages([
("system",
"""
아래의 문맥에만 근거하여 사용자 질문에 답변하세요:
<context>
{context}
</context>
"""
),
("placeholder", "{chat_history}"),
("human", "{input}"),
])
stuff_documents_chain = create_stuff_documents_chain(
llm=llm,
prompt=retrieval_qa_chat_prompt
)
해당부분은 사용자에게 받은 질문을 가지고 관련성이 가장높은 문서를 검색한다.
rephrase_prompt = PromptTemplate.from_template(
"""
주어진 대화와 후속 질문을 바탕으로 후속 질문을 독립적인 질문으로 바꾸세요.
대화 기록:
{chat_history}
후속 질문:
{input}
독립적인 질문:
"""
)
# 히스토리 인식 검색기를 생성합니다.
history_aware_retriever = create_history_aware_retriever(
llm=llm,
retriever=vector_db.as_retriever(),
prompt=rephrase_prompt
)
검색체인을 생성하고 실행해본다.
qa = create_retrieval_chain(
retriever=history_aware_retriever,
combine_docs_chain=stuff_documents_chain
)
# 검색 체인을 실행하여 결과를 얻습니다.
result = qa.invoke(
input={"input": query, "chat_history": chat_history}
)
{
'query': '배송이언제돼?',
'result': '고객님, 주문하신 상품은 오늘 출발 예정이며, 2~3일 내에 도착할 예정입니다.
정확한 배송 일정은 배송 조회를 통해 확인하실 수 있습니다. 배송 기간은 지역에 따라 다를 수 있지만,
평균적으로 2~3일 정도 소요됩니다. 더 자세한 정보가 필요하시면 배송 추적 서비스를 이용해 주시기 바랍니다.',
'source_documents': [
Document(
id='eec474e3-ee66-452c-b93a-8f96fba13586',
metadata={
'dataset_language': 'ko',
'dataset_type': 'question-response pairs',
'domain': 'customer service',
'data_format': 'JSON',
'source': 'user-provided',
'creation_date': '2025-01-14',
'tags': ['customer service', 'e-commerce', 'shipping', 'returns', 'product inquiry']
},
page_content='Input: 배송일을 조정할 수 있나요?\\nResponse: 배송일 조정은 상품 출발 전에 가능하며, 고객센터를 통해 조정이 가능합니다.'
),
]
}
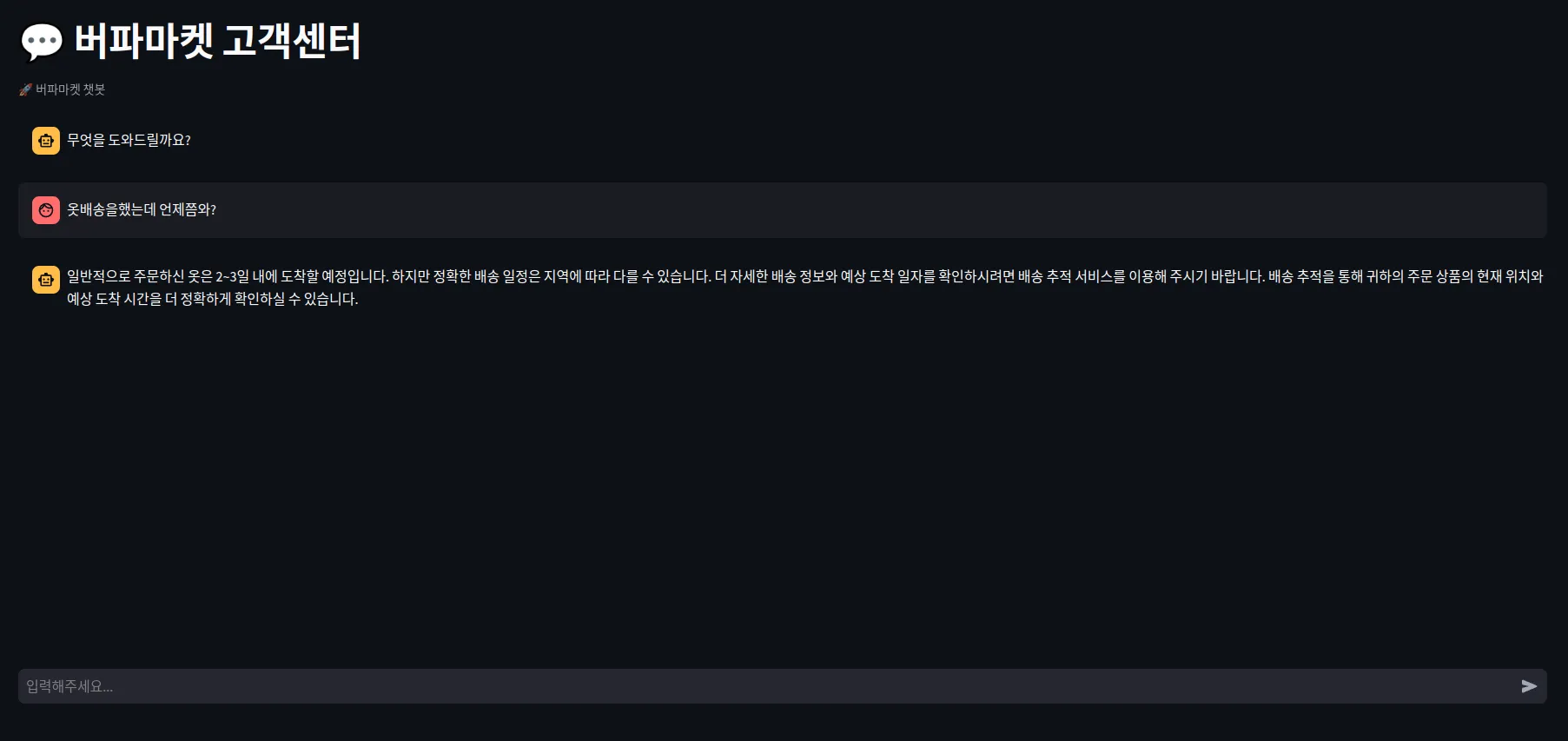
3. 화면구현
from typing import Set
from chatbot import chatbot
import streamlit as st
from streamlit_chat import message
st.set_page_config(page_title="버파마켓 고객센터", layout="wide")
st.title("💬 버파마켓 고객센터")
st.caption("🚀 버파마켓 챗봇")
if "chat_answers_history" not in st.session_state:
st.session_state["chat_answers_history"] = []
if "user_prompt_history" not in st.session_state:
st.session_state["user_prompt_history"] = []
if "chat_history" not in st.session_state:
st.session_state["chat_history"] = [{"role": "assistant", "content": "무엇을 도와드릴까요?"}]
for msg in st.session_state["chat_history"]:
st.chat_message(msg["role"]).write(msg["content"])
if prompt := st.chat_input(placeholder="입력해주세요..."):
# 첫 메시지가 들어오면 처음에 들어가 있던 "assistant" 메시지를 pop
if len(st.session_state["chat_history"]) == 1 and st.session_state["chat_history"][0]["role"] == "assistant":
st.session_state["chat_history"].pop()
st.session_state["user_prompt_history"].append(prompt)
st.session_state["chat_history"].append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
with st.spinner("답변 생성중..."):
generated_response = chatbot(
query=prompt,
chat_history=st.session_state["chat_history"],
)
formatted_response = f"{generated_response['result']}"
st.session_state["chat_answers_history"].append(formatted_response)
st.session_state["chat_history"].append({"role": "assistant", "content": formatted_response})
st.chat_message("assistant").write(formatted_response)
'🧑💻 실무 개발 & 시스템' 카테고리의 다른 글
| Milvus을 사용해서 임베팅 모델 비교해보기 (1) | 2025.01.22 |
|---|---|
| Langchain 벡터 데이터베이스 구축 (Milvus) (3) | 2025.01.21 |
| Langchain agent, csv 데이터를 활용한 챗봇 구현(2) (4) | 2024.12.23 |
| AI Langchain RAG 적용기 CS 정보 데이터 검색(1) (3) | 2024.12.17 |
| jest를 사용한 unit test(2). ( 개인공부 ) (2) | 2024.12.11 |